
Tiskalniki omenjene Xeroxove družine po celotni površini vsakega barvnega izpisa natisnejo ponavljajočo se skrito kodo. Iz naših preizkusov nekaterih drugih tiskalnikov (o tem v samostojnem članku) smo ugotovili, da je v večini primerov dokaj enostavno opaziti ponavljajoči se vzorec in omejiti eno polje. Kodo predstavlja polje velikosti 15 stolpcev in 8 vrstic, v katerih (celicah) obstajajo ali ne obstajajo rumene pike. Skupaj je pik lahko 120, vendar vse nimajo funkcije prenosa informacij. Nekaj jih je v vlogi paritetnih bitov za ugotavljanje napak, s pomočjo katerih lahko hitro vidimo, ali smo kodo prebrali pravilno ali ne. V konkretnem primeru družine tiskalnikov DocuColor koda skriva deset zlogov (bajtov) uporabnih podatkov, njen skrajni potencial pa je 14 sedembitnih podatkov. Rumene pike so majhne, naša ocena je, da so velike od 0,1 in 0,2 milimetra. Razmak med pikami je približno en milimeter, kar daje »golo« velikost kode 7 x 14 mm. Tako je doseženo, da je koda natisnjena tudi na tistem delu slike, ki jo morda natisnemo in nato izrežemo iz natisnjenega lista. Saj veste, kam pes taco moli. Na nelegalno tiskanje oziroma, bolje rečeno, ponarejanje denarja.
KAKO JE ŠIFRIRAL XEROX
| Stolpec | Informacija, ki jo nosi |
| 1 | Liha pariteta |
| 2 | Čas tiskanja: minute, ko je bila stran natisnjena |
| 3 ,4 in 9 | Neuporabljeno |
| 5 | Čas tiskanja: ura tiskanja, vendar ni jasno, po katerem času (kako je ta nastavljen v tiskalniku) |
| 6 | Datum tiskanja: dan |
| 7 | Datum tiskanja: mesec |
| 8 | Datum tiskanja: leto (brez stoletja, leto 2005 zapišejo na primer kot 05) |
| 10 | Ločilec med dvema blokoma podatkov. |
| 11,12,13 in 14 | Serijska številka tiskalnika. Več števil sestavljeni (in ne seštetih) da serijsko številko. |
| 15 | Ni znano, ali se tudi v tem stolpcu skrivajo kakšni podatki. |
KAKO SMO DEŠIFRIRALI
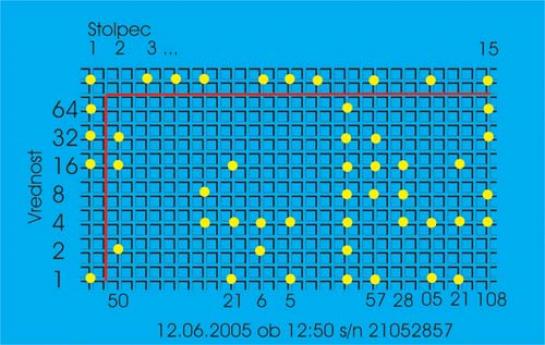
Zdaj pa k dešifriranju, ki je nazorno predstavljeno na gornji sliki. Prva vrstica in skrajno levi stolpec predstavljata tako imenovane zaščitne paritetne bite po načelu lihe paritete. Enostavno povedano, to pomeni, da mora biti v vsakem stolpcu in v vsaki vrstici, izjema je zgolj prva vrstica, liho število pik. Sistem samodejno doda oziroma ne doda pike v paritetni stolpec oziroma vrstico, glede na število pik v vrsticah oziroma stolpcih, namenjenih zapisu podatkov. Ko beremo kodo, nam ti podatki pomagajo pri zaznavanju, ali je bilo branje pravilno ali nepravilno. Če je pri našem branju v kakšni vrstici ali stolpcu (izjema je, kot smo dejali, le prva vrstica) sodo število pik, smo lahko prepričani, da smo zadevo prebrali napačno. Če pa so števila liha, potem smo lahko skoraj prepričani, da smo prebrali pravilno, ali pa, da smo se pri branju ene vrstice ali stolpca zmotili dvakrat, kar je pri tako malo podatkih (pikah) malo verjetno.
Gremo naprej. Vsak stolpec dešifriramo od spodaj navzgor. Najnižja pika ima vrednost 1, sledijo pa dvojiške vrednosti 2, 4, 8, 16, 32 in 64. Podatek, ki ga skriva stolpec (7 pik), dobimo, če seštejemo vrednosti, ki pripadajo celici v stolpcu, v kateri je natisnjena pika. Poglejmo si primer stolpca – drugega z leve. Pike so pri številki 2, 16 in 32, seštevek je torej 50. V vsak 7-bitni stolpec − ne pozabimo, da je en bit paritetni − lahko torej zapišemo poljubno število v intervalu med 0 in 128.
Serijska številka tiskalnika je običajno daljši niz številk, zatorej je za njen zapis potrebnih več stolpcev. Če je številka dolga 6 številk, potem uporabijo tri, pri osemštevilčni serijski številki pa štiri stolpce. Gre pa za preprosto zadevo. Na primer, serijsko številko 023567 sestavljajo v ustrezne stolpce zapisana števila 02, 35 in 67.
Koda pri tiskalnikih Xerox je bila prva odkrita in tudi prva dešifrirana. Ali se bo zadeva nadaljevala z dešifriranjem tudi drugih kod, je odvisno od interesa javnosti. Po našem mnenju je dovolj, da uporabniki vedo, da kode obstajajo. Najbolj neprimerno za demokratične družbe je to, da so preprosto tiho ali da obstoj takšnih zaščitnih mehanizmov preprosto zanikajo.
Izbrani še vedno aktualni članki iz leta 2006